If you are like me you worry about unintentionally running malicious JavaScript from your web browser. JavaScript is the hidden code of a website that can manipulate elements of the site, perform animations, access device sensors and even fetch additional web resources from the internet in the background. Unfortunately, this is an attack vector that is exploited by attackers every day. In a prior article, I showed how you can even take control of a victim’s browser and perform distributed password cracking with JavaScript.
If you look for browser extensions on the market, the only capabilities are the ability to whitelist/blacklist certain JS scripts that the site wants to load for it to work. You have a rather rudimentary way of determining a potential malicious script. Usually you can only identify based only on a URL.
What if we would pre-process the JavaScript files that are about to load and perform searches for known key identifiers of a malicious payload. Let’s build our own solution where we can add multiple rules and apply to the target script. Then deliver a threat severity rating for us to determine a blacklist and prevent the browser from fetching and loading the code.
Building the extension
Building a Chromium-based extension is quite simple. An extension requires a folder and two files to be imported into the browser through the extensions page.
Create a folder and make the two files, manifest.json and background.js.
The manifest.json file is a required file where Chromium imports the extensions configuration and load files. Without it you cannot run your extension. It also allows us to set the permissions that the extension will use in the code.
{
"name": "JavaScript Hunter",
"version": "1.0",
"manifest_version": 2,
"background": {
"scripts": ["jquery-3.5.1.min.js", "background.js"]
},
"permissions": [
"webRequest",
"webRequestBlocking",
"<all_urls>"
]
}Here we name the extension, version, and manifest version. We will be running a background script so we list that script we will be using for the extension.
Note that our code will be using the JQuery library. Download the library from the following CDN into our folder. Make sure you reference it first in the manifest.
wget https://code.jquery.com/jquery-3.5.1.min.jsThe extension will have to intercept all requests and determine if the request needs to be blocked or not. webRequest and webRequestBlocking permissions will allow us to analyze the requests and block on detection. The <all_urls> permission gives us the ability to look at all URLs instead of a specific website.
The logic
We have our manifest. We have JQuery downloaded and imported into our project folder. Now we need to build our background script that will analyze the requests and parse the JavaScript scripts being requested from our browser. Open the background.js file in your project folder.
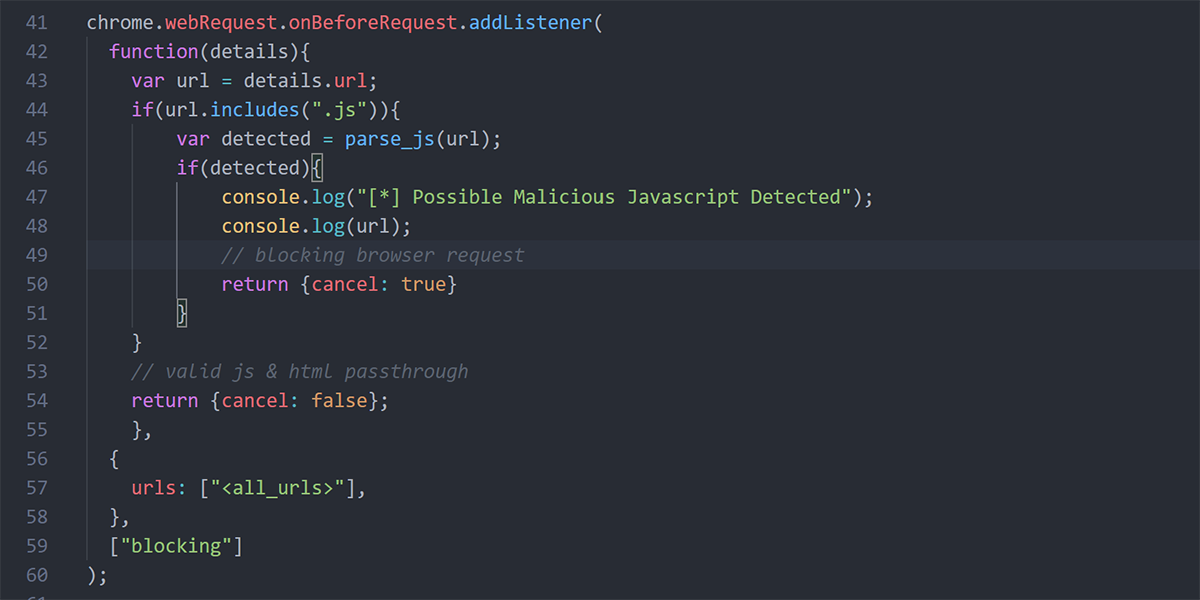
chrome.webRequest.onBeforeRequest.addListener(
function(details){
var url = details.url;
if(url.includes(".js")){
var detected = parse_js(url);
if(detected){
console.log("[*] Possible Malicious Javascript Detected");
console.log(url);
// blocking browser request
return {cancel: true}
}
}
// valid js & html passthrough
return {cancel: false};
},
{
urls: ["<all_urls>"],
},
["blocking"]
);The webRequest.onBeforeRequest listener will listen for all browser requests by setting the urls parameter with <all_urls>. We then pass each request through a function that detects if a request is a JavaScript file or not. If the request is a JS file, it will parse the request through our detection function to determine if file is malicious. All other traffic will be allowed by setting the cancel field as false.
If the resource being requested is a JavaScript file, we pre-download it in the our separate background process. This will be downloaded into a string so if its malicious it can be blocked before the browser renders it in its JavaScript engine. To do this, we fetch the resource with an AJAX call that downloads it into the string for analysis. When the call is successful, it gets passed on to the scanning phase.
function parse_js(url){
var detection = false;
$.ajax({
type: "get",
url : url,
crossDomain:true,
cache:false,
async:false,
success: function(response){
detection = scan_js(response);
},
error: function(jqxhr) {
console.log(jqxhr);
return false;
}
});
return detection;
}Scanning the request
If you are aware of Yara you know its a malicious file scanner that determines the threat severity based on certain strings or text in the file or binary. We will being using regular expressions to search the file for identifiers of known malicious JavaScript in a similar way. We can create rules in an array and allow an iteration a test of each over every JS scripts.
var rules = [
// cred: josh berry
// obfuscated
RegExp(/eval\(([\s]+)?(unescape|atob)\(/, "gi"),
RegExp(/var([\s]+)?([a-zA-Z_$])+([a-zA-Z0-9_$]+)?([\s]+)?=([\s]+)?\[([\s]+)?\"\\x[0-9a-fA-F]+/, "gi"),
RegExp(/var([\s]+)?([a-zA-Z_$])+([a-zA-Z0-9_$]+)?([\s]+)?=([\s]+)?eval;/, "gi"),
// possibly packed
RegExp(/(atob|btoa|;base64|base64,)/, "gi"),
RegExp(/([A-Za-z0-9]{4})*([A-Za-z0-9]{2}==|[A-Za-z0-9]{3}=|[A-Za-z0-9]{4})/, "g"),
];Since JavaScript is very difficult to detect and creates a lot of false positives. We can set an alert on a certain severity level to pass back to our main listener to display or not.
function scan_js(js){
var severity = 0;
rules.forEach(function (rule) {
if(rule.test(js))
severity++;
});
return severity > 1 ? true : false;
}Here is the bread and butter of the extension. Our scan_js function will take the JS file we downloaded and iterate it over our rules. If a rule is detected by the regular expression, it will add the hit to our severity counter. If it matches two rules, it will be detected.
That’s it! Now let’s import our extension into Chromium.
Importing the extension into Chromium.
Importing the extension is fairly straight forward. Go to the following address in the address bar to get to the Extensions page.
chrome://extensions/In order to load an “unpacked” extension, you will need to toggle Developer Mode on. Then hit “Load unpacked” to select the project folder.
Once you select your project folder you should see your extension loaded.
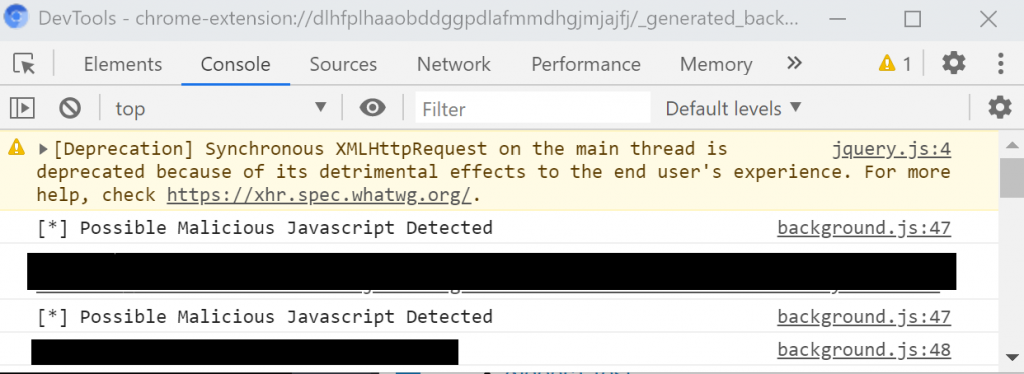
Obviously this demonstration is rudimentary. Detection alerts should be done visually but for this we just logged an alert in the console. To get access to this specific console we are writing to, you will need to click on “background page” on your extension entry to access it.
Go to another tab and create some traffic. If a potentially malicious JavaScript file is requested, an alert to console will be made and blocked from being requested by the browser.
Wrap up
In this article I showed you how to perform a pre-process on your browser to block a potentially risky JavaScript file from being rendered. Although just a proof of concept, I believe this is the route to tackle detecting malicious code before the browser runs it in its JavaScript engine and starts a potential attack. The detector is only as good as its rules and determining the threat level you want to risk as many of these rules bring the headache of false positives. But I was impressed by the speed of just a few rules so it’s worth taking this further. Since there is nothing on the market that is actually performing analysis on JS code before it gets run, I will be experimenting more and building out this extension in the future so stay tuned for updates.
michael rinderle
Michael has been a professional in the information technology field for over 10 years, specializing in software engineering and systems administration. He studied network security and holds a software engineering degree from Milwaukee Area Technical College with thousands of hours of self taught learning as well. He mainly writes about technology, current events, and coding. Michael also is the founder of Sof Digital, an U.S. based software development Firm. His hobbies are archery, turntablism, disc golf and rally racing.
Comments are closed, but trackbacks and pingbacks are open.